什麼是相關分析 (Correlation Analysis)?
相關分析是一種統計工具,用來評估兩個或多個變數之間聯繫的程度和趨勢。它主要考察當一個變數發生變化時,另一個變數是否會跟隨增加、減少,或者毫無明顯模式。在數據科學以及各種研究領域,這項分析就像探索數據的起點,能讓分析師迅速發現隱藏的連結,為後續的模型建構或因果探討鋪路。
例如,假設我們觀察學生學習時間和考試分數的關係,如果兩者呈現正向聯繫,就表示多花時間學習通常帶來更高的成績。相反,商品價格上升時銷售量下降,便是負向聯繫的例子。相關分析的基礎在於相關係數,這是一個從負一到正一的數值,它不僅顯示聯繫的方向,還反映強弱程度。
不過,有一點必須牢記:相關並不代表因果。這是統計學中經常被重申的原則。即使兩個變數高度同步,也不能斷定其中一個直接導致另一個的變化。以夏季冰淇淋銷售量和溺水事件為例,兩者可能同時上升,但真正原因是高溫天氣,而非冰淇淋引發事故。要深入了解因果,則需透過嚴格實驗或更複雜的模型。更多細節可參考加州大學柏克萊分校對相關性的解釋。
相關分析的常見類型與選擇指南
選擇合適的相關係數類型是分析成功的關鍵,這取決於數據的特徵、分佈情況以及變數間的互動模式。下面我們來介紹三種主流類型:Pearson、Spearman 和 Kendall,讓讀者能根據實際需求做出判斷。
Pearson 相關係數 (Pearson Correlation Coefficient)
Pearson 相關係數是最常見的測量方式,它專注於兩個連續變數之間的線性聯繫強度和方向。
適用情境包括:
兩個變數皆為連續數據,例如身高、體重或溫度記錄。
變數間顯示線性趨勢,透過散點圖可見直線樣貌。
數據大致符合常態分佈。
避免明顯的離群值干擾。
計算公式涉及共變異數除以標準差乘積,雖然手算複雜,但軟體工具能輕鬆處理。結果的 r 值從負一到正一:正一為完美正線性,負一為完美負線性,零則無線性聯繫。
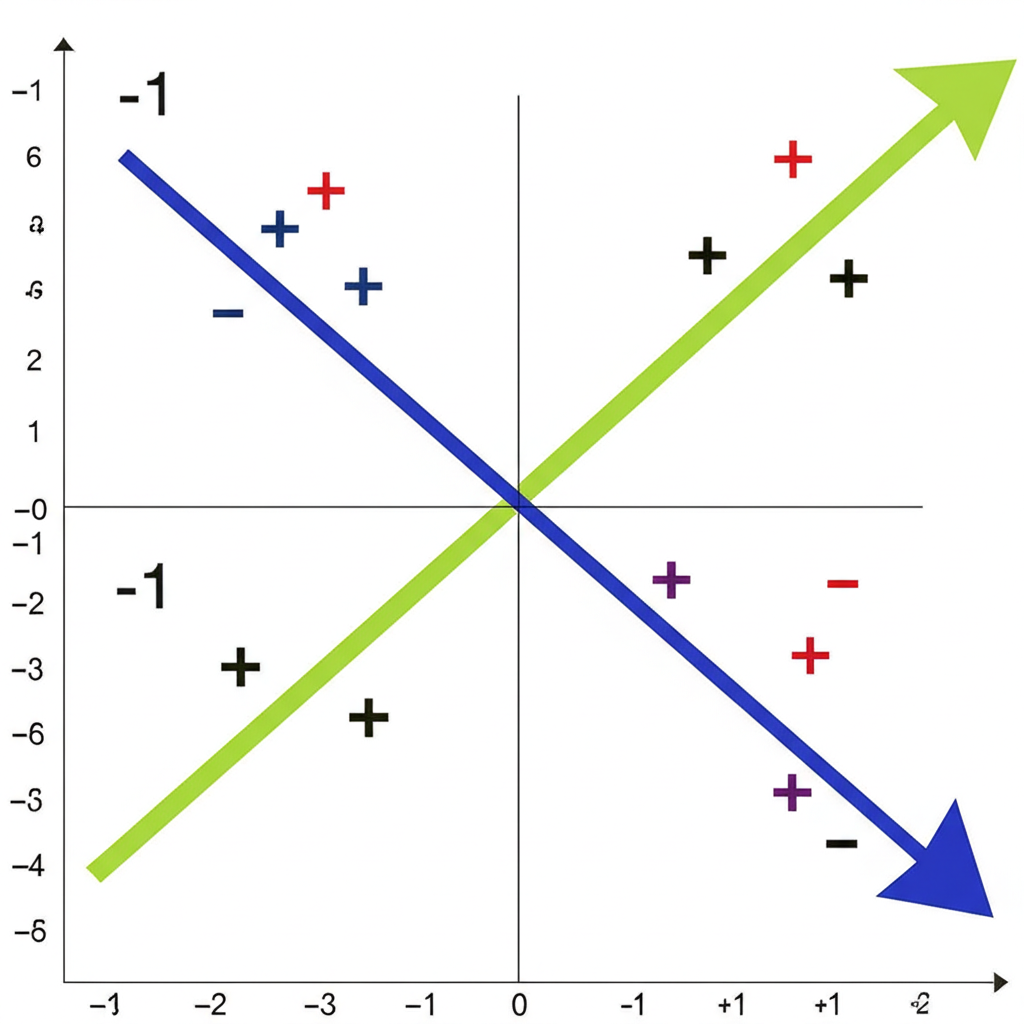
Spearman 等級相關係數 (Spearman’s Rank Correlation Coefficient)
Spearman 係數屬於非參數方法,評估兩個變數的單調關係強度和方向。它不依賴常態分佈或線性假設,只要變數變化方向一致即可。
適合序數數據如滿意度評級,或非正態的連續變數。
變數呈單調趨勢,一方上升另一方也總是上升或下降。
對離群值較不敏感。
與 Pearson 不同,Spearman 先將數據轉為排名,再套用類似計算。解讀方式相似,值從負一到正一,反映單調聯繫的強度。
Kendall 等級相關係數 (Kendall’s Tau Correlation Coefficient)
Kendall 係數同樣是非參數等級方法,測量單調關係的強度,與 Spearman 相近。
適用於序數或非正態連續數據。
尤其適合小樣本或有許多重複等級的資料。
計算基於一致和不一致數據對的比對,在小樣本或重複值多時更穩定,結果絕對值通常小於 Spearman。解讀同樣從負一到正一,強調單調強度。
相關分析類型選擇決策樹
為了簡化選擇,我們設計了一個決策流程,幫助根據數據特徵快速決定。
相關分析類型選擇決策流程圖
1. 檢查變數類型:
都是連續變數嗎?
是 → 步驟 2
否 → 步驟 3
2. 檢查連續變數的關係與分佈:
散點圖顯示線性且近似常態嗎?
是 → 選擇 Pearson 相關係數
否(單調但非線性)→ 選擇 Spearman 或 Kendall 相關係數
3. 檢查非參數情況下的偏好:
樣本小或重複等級多嗎?
是 → 選擇 Kendall 相關係數
否 → 選擇 Spearman 相關係數
這個流程能確保分析符合數據本質,提升結果可靠性。
如何解讀相關分析結果?係數強度與顯著性
解讀相關結果時,不能只盯著單一數字,還要考慮強度、方向和統計可靠性,這樣才能得出全面結論。
相關係數的數值意義 (-1 到 +1)
係數絕對值顯示強度,符號決定方向。
正相關(接近 +1):一個變數上升,另一個跟隨上升,值越大越強。
負相關(接近 -1):一方上升,另一方下降,值越接近負一越強。
無相關(接近 0):無明顯線性或單調聯繫。
以下是強度參考表(依領域調整):
| 相關係數絕對值 | 關係強度 |
| :————- | :——- |
| 0.00 – 0.19 | 非常弱或無關 |
| 0.20 – 0.39 | 弱相關 |
| 0.40 – 0.59 | 中等相關 |
| 0.60 – 0.79 | 強相關 |
| 0.80 – 1.00 | 非常強相關 |

P 值與統計顯著性
P 值幫助判斷相關是否僅為隨機結果。
P 值是假設無相關時,觀察到此結果的機率。
若 P 值低於 0.05 或 0.01,則視為顯著,拒絕無相關假設。
若高於閾值,則可能為巧合。
即使係數大,若 P 值不顯著,仍需謹慎解釋。
視覺化呈現:散佈圖的應用
散點圖是檢視關係的最佳視覺工具,能提供係數之外的洞察。
它能顯示線性或非線性模式:點沿直線為線性,曲線則非線性。
密集度和方向反映強度和正負。
易發現離群值,這些可能扭曲計算。
還能揭露群聚或變異不均等問題。
在報告中,結合散點圖能讓解釋更生動可靠。
相關分析的實務操作指南:多工具教學
理論了解後,實際操作才能鞏固知識。以下示範在常見軟體中執行相關分析,從入門到進階。
在 Microsoft Excel 中執行相關分析
Excel 適合初學者處理基本 Pearson 分析。
步驟:
1. 啟用資料分析工具庫:檔案 > 選項 > 增益集 > 勾選分析工具庫 > 確定。
2. 準備數據:將變數置於相鄰欄位。
3. 執行:
點擊資料 > 資料分析 > 相關係數 > 確定。
輸入範圍選取數據(含標題)。
勾選標記在第一列。
選擇輸出位置 > 確定。
結果為係數矩陣,對角線為 1,其他為變數間 Pearson 值,如 A-B 相關。
在 SPSS 中執行相關分析
SPSS 以圖形介面聞名,適合統計分析。
步驟:
1. 載入數據。
2. 執行:
分析 > 相關 > 雙變數。
移入變數。
選擇係數類型(Pearson、Spearman 或 Kendall’s tau-b)。
選雙尾檢定,勾選顯著標記 > 確定。
輸出顯示矩陣,每格含係數、P 值 (Sig. (2-tailed)) 和 N,星號標示顯著。
使用 Python (Pandas & SciPy) 進行相關分析
Python 透過庫實現高效分析。
簡要代碼示例:
“`python
import pandas as pd
from scipy.stats import pearsonr, spearmanr, kendalltau
# 假設您有一個名為 df 的 Pandas DataFrame
# df = pd.read_csv(‘your_data.csv’)
# 示例數據
data = {
‘VariableA’: [10, 20, 30, 40, 50, 60, 70, 80, 90, 100],
‘VariableB’: [2, 4, 6, 8, 10, 12, 14, 16, 18, 20],
‘VariableC’: [100, 90, 80, 70, 60, 50, 40, 30, 20, 10],
‘VariableD’: [1, 2, 3, 4, 5, 1, 2, 3, 4, 5] # 序數型或非線性單調
}
df = pd.DataFrame(data)
# 計算所有連續變數之間的 Pearson 相關係數矩陣
pearson_corr_matrix = df.corr(method=’pearson’)
print(“Pearson Correlation Matrix:\n”, pearson_corr_matrix)
# 計算所有變數之間的 Spearman 相關係數矩陣
spearman_corr_matrix = df.corr(method=’spearman’)
print(“\nSpearman Correlation Matrix:\n”, spearman_corr_matrix)
# 計算特定兩變數之間的 Pearson 相關係數和 P 值
corr_val_pearson, p_val_pearson = pearsonr(df[‘VariableA’], df[‘VariableB’])
print(f”\nPearson correlation between A and B: {corr_val_pearson:.3f}, P-value: {p_val_pearson:.3f}”)
# 計算特定兩變數之間的 Spearman 相關係數和 P 值
corr_val_spearman, p_val_spearman = spearmanr(df[‘VariableA’], df[‘VariableD’])
print(f”Spearman correlation between A and D: {corr_val_spearman:.3f}, P-value: {p_val_spearman:.3f}”)
# 計算特定兩變數之間的 Kendall 相關係數和 P 值
corr_val_kendall, p_val_kendall = kendalltau(df[‘VariableA’], df[‘VariableD’])
print(f”Kendall correlation between A and D: {corr_val_kendall:.3f}, P-value: {p_val_kendall:.3f}”)
“`
Pandas 的 corr() 生成矩陣,SciPy 函數提供係數與 P 值。
使用 R 語言進行相關分析
R 語言以統計功能強大,適合深入分析。
簡要代碼示例:
“`R
# 假設您有一個名為 my_data 的數據框
# my_data <- read.csv("your_data.csv")
# 示例數據
my_data <- data.frame(
VariableA = c(10, 20, 30, 40, 50, 60, 70, 80, 90, 100),
VariableB = c(2, 4, 6, 8, 10, 12, 14, 16, 18, 20),
VariableC = c(100, 90, 80, 70, 60, 50, 40, 30, 20, 10),
VariableD = c(1, 2, 3, 4, 5, 1, 2, 3, 4, 5) # 序數型或非線性單調
)
# 計算所有變數之間的 Pearson 相關係數矩陣
pearson_corr_matrix <- cor(my_data, method = "pearson")
print("Pearson Correlation Matrix:")
print(pearson_corr_matrix)
# 計算所有變數之間的 Spearman 相關係數矩陣
spearman_corr_matrix <- cor(my_data, method = "spearman")
print("\nSpearman Correlation Matrix:")
print(spearman_corr_matrix)
# 計算特定兩變數之間的 Pearson 相關係數和 P 值
# 使用 `cor.test` 函數,它會提供更詳細的結果
cor_test_pearson <- cor.test(my_data$VariableA, my_data$VariableB, method = "pearson")
print("\nPearson correlation test between A and B:")
print(cor_test_pearson)
# 計算特定兩變數之間的 Spearman 相關係數和 P 值
cor_test_spearman <- cor.test(my_data$VariableA, my_data$VariableD, method = "spearman")
print("\nSpearman correlation test between A and D:")
print(cor_test_spearman)
# 計算特定兩變數之間的 Kendall 相關係數和 P 值
cor_test_kendall <- cor.test(my_data$VariableA, my_data$VariableD, method = "kendall")
print("\nKendall correlation test between A and D:")
print(cor_test_kendall)
```
cor() 產生矩陣,cor.test() 給詳細檢定,包括 P 值和信賴區間。
相關分析的常見應用場景
相關分析在多個行業發揮作用,幫助從數據中提煉洞察,支持決策過程。
在市場研究中,可檢視廣告預算與銷售表現的聯動,或價格調整對購買行為的影響,從而優化產品策略。
金融領域常用來分析資產收益的相關性,建構分散風險的投資組合,或追蹤經濟指標對市場的波及。
醫學研究則用它探討生活習慣如運動量與健康指標的關聯,或藥效與劑量的關係。
教育與心理學可評估學習投入對成績的影響,或不同情緒因素間的互動。
工程品質控制則檢測生產變數如溫度對缺陷率的影響,改善流程效率。
這些應用顯示相關分析的廣泛實用性,從初步探索到策略規劃皆不可或缺。
相關分析的限制與常見誤區
雖然強大,相關分析仍有界限,忽略這些可能導致誤判。以下探討主要問題,並提供避免之道。
相關性不等於因果關係 (再次強調)
這是核心警示。即使聯繫緊密,也不能推論因果。
例如,兒童鞋碼與數學成績正相關,但鞋碼不是原因,年齡才是共同驅動因素。
因果需證明時間順序和排除干擾,相關僅顯示同步變化。
異常值 (Outliers) 的影響
離群值是偏離主流的數據點,可能來自錯誤或特殊事件。
它們易扭曲 Pearson 係數,甚至反轉方向。例如,本該弱正相關的數據,一個極端點可能製造假負相關。
先用散點圖檢查,視情況移除、轉換或改用 Spearman/Kendall。
非線性關係的限制
Pearson 只抓線性,若為曲線如 U 形,係數可能誤示無關。
如焦慮與表現的倒 U 關係,中等焦慮最佳,Pearson 會低估。
用散點圖確認,若非線性,轉 Spearman 或曲線模型。
資料分佈與選擇正確方法
Pearson 需近似常態連續數據,違反則結果偏差。
偏態數據會誤導線性評估。
改用非參數方法如 Spearman,確保匹配假設。
偽相關 (Spurious Correlation)
這是無意義的假聯繫,常由隱藏變數或巧合引起。
如乳酪消耗與意外死亡的相關,純屬偶然。更多例子見Spurious Correlations 網站。
結合領域知識,檢查潛在因素,避免盲信。
進階概念:正則相關分析 (Canonical Correlation Analysis) 簡介
當面對兩組變數時,單對單分析不夠全面,正則相關分析 (CCA) 能捕捉整體互動。
CCA 尋找兩組的線性組合,使其相關最大化,即創建正則變數。
例如,從消費者特徵組合成一指標,再與購買行為組合成另一,計算其 Pearson 值,可迭代找出多對。
應用包括市場中人口變數與行為的整體關聯、心理特質與健康的連結,或環境對生長的影響。
CCA 擴展傳統方法,適合複雜多變量情境。
總結:精準掌握數據關係的基石
相關分析是數據領域的基礎利器,能量化變數聯繫的強弱與方向。從 Pearson 的線性測量,到 Spearman 和 Kendall 的單調評估,再到 CCA 的多組探討,各有適用範圍。本文涵蓋定義、類型、解讀,以及在 Excel、SPSS、Python 和 R 的操作,還強調限制如非因果和離群影響。
要善用它,需選對方法、檢視 P 值與視覺圖表,並永遠警惕相關不即因果。避開偽相關與非線性陷阱,你的分析將更精準,從數據中萃取出真正價值,支撐可靠決策。
常見問題 (FAQ)
什麼是相關分析,它在數據研究中扮演什麼角色?
相關分析是一種統計方法,用於衡量兩個或多個變數之間關係的強度和方向。它在數據研究中扮演著基礎性的角色,幫助我們:
- 探索性數據分析:快速識別數據集中變數之間的潛在關係。
- 假設生成:根據觀察到的相關性提出更深入的研究假設。
- 預測模型基礎:為建立預測模型(如迴歸分析)提供變數選擇的依據。
- 風險評估與決策:在金融、市場研究等領域評估變數之間的聯動性,輔助決策。
Pearson、Spearman 和 Kendall 這三種相關係數有何不同,我該如何選擇?
- Pearson 相關係數:適用於連續型變數之間的線性關係,要求數據近似常態分佈。
- Spearman 等級相關係數:適用於序數型變數或非常態分佈的連續型變數,衡量變數之間的單調關係(不一定是線性)。它基於數據的等級而非原始數值計算。
- Kendall 等級相關係數:與 Spearman 類似,也衡量單調關係,但通常認為在小樣本量或存在大量相同等級的情況下更為穩健。
選擇時,請根據您的數據類型(連續、序數)、數據分佈(常態、非常態)以及您想探討的關係類型(線性、單調)來判斷。
相關係數的數值代表什麼意義,以及如何判斷相關的強度?
相關係數的值介於 -1 到 +1 之間:
- 符號:正值 (+) 表示正相關(一個變數增加,另一個也增加);負值 (-) 表示負相關(一個變數增加,另一個減少)。
- 絕對值:絕對值越接近 1,表示關係越強;越接近 0,表示關係越弱。
判斷強度的一般參考標準(僅供參考,應結合領域知識):
- 0.00 – 0.19:非常弱或無關
- 0.20 – 0.39:弱相關
- 0.40 – 0.59:中等相關
- 0.60 – 0.79:強相關
- 0.80 – 1.00:非常強相關
相關分析的結果可以證明變數之間存在因果關係嗎?
不可以。這是相關分析最重要的限制之一。相關性僅表示兩個變數之間存在共同的變化趨勢,但不能證明其中一個是另一個的原因或結果。要證明因果關係,需要更嚴格的實驗設計(如隨機對照實驗)或其他進階的統計模型,並排除其他潛在的解釋。
如何在 Excel 或 SPSS 等常用軟體中執行相關分析?
- Excel:需啟用「資料分析工具庫」。在「資料」標籤下選擇「資料分析」>「相關係數」,然後選擇您的數據範圍。
- SPSS:在菜單欄中選擇「分析 (Analyze)」>「相關 (Correlate)」>「雙變數 (Bivariate…)」,然後將變數移到「變數」框中,並選擇所需的相關係數類型(Pearson, Spearman, Kendall)。
詳細步驟請參考文章中的「相關分析的實務操作指南:多工具教學」部分。
數據中存在異常值或非線性關係時,會對相關分析結果產生什麼影響?
- 異常值 (Outliers):單個或幾個異常值可能會嚴重扭曲 Pearson 相關係數,使其偏離真實關係,甚至改變相關的方向。對此,應先視覺化數據,並考慮移除異常值、轉換數據或使用非參數方法(如 Spearman)。
- 非線性關係:Pearson 相關係數只能捕捉線性關係。如果變數之間存在強烈的非線性關係(如 U 形),Pearson 係數可能接近零,錯誤地顯示兩者無關。此時應透過散佈圖識別,並考慮使用非參數方法。
除了基本的相關分析,還有哪些進階的相關性衡量方法,例如正則相關分析?
是的,除了基本的兩變數相關分析,還有許多進階方法,例如:
- 偏相關分析 (Partial Correlation):衡量在控制一個或多個其他變數影響後,兩個變數之間的關係。
- 多重相關分析 (Multiple Correlation):衡量一個變數與一組其他變數之間的線性關係強度。
- 正則相關分析 (Canonical Correlation Analysis, CCA):探討兩組變數集之間的整體關係,尋找兩組變數中線性組合的最大相關性。這對於理解複雜系統中多個變數群組之間的互動非常有用。
在進行相關分析時,有哪些常見的誤區或需要特別注意的事項?
常見的誤區與注意事項包括:
- 相關性不等於因果關係:這是最重要的原則。
- 異常值的影響:異常值可能扭曲結果,應仔細檢查和處理。
- 非線性關係的盲點:Pearson 係數對非線性關係無效,需透過散佈圖判斷。
- 偽相關:看似相關但實為偶然或由潛在變數引起的虛假關聯。
- 分佈假設:確保所選相關係數符合數據的分佈假設(如 Pearson 需要近似常態分佈)。
- 同質性:數據應來自同一群體,混合不同群體可能產生誤導性相關。
我可以將變異數分析 (ANOVA) 的結果與相關分析結合使用嗎?
可以,但它們回答的是不同的問題:
- ANOVA 主要用於比較兩個或多個類別變數群組之間的連續變數均值是否存在統計上的顯著差異。
- 相關分析 主要用於衡量兩個連續變數之間的關係強度和方向。
例如,您可以先用 ANOVA 檢定不同實驗組的平均得分是否有顯著差異,然後再用相關分析探討在各組內,某個連續性指標(如學習時間)與得分之間的關係。兩者可以互補,提供更全面的數據洞察。
如何根據業務或研究目的,有效運用相關分析來洞察數據?
有效運用相關分析的關鍵在於結合您的業務或研究背景:
- 明確目標:首先明確您想了解哪些變數之間的關係。
- 數據預處理:清理數據,處理缺失值和異常值。
- 視覺化探索:始終從散佈圖開始,直觀了解關係類型。
- 選擇正確方法:根據數據特徵選擇 Pearson, Spearman 或 Kendall。
- 解釋結果:不僅看係數大小,還要看 P 值,並結合專業知識解釋。
- 超越相關:如果需要證明因果,則需進一步的實驗或迴歸分析。
- 發現潛在變數:思考是否存在共同的潛在變數可能導致觀察到的相關性。
相關分析應作為探索和理解數據的第一步,為更深入的分析和決策提供方向。
搶先發佈留言